文生图/图生图基本原理
基础
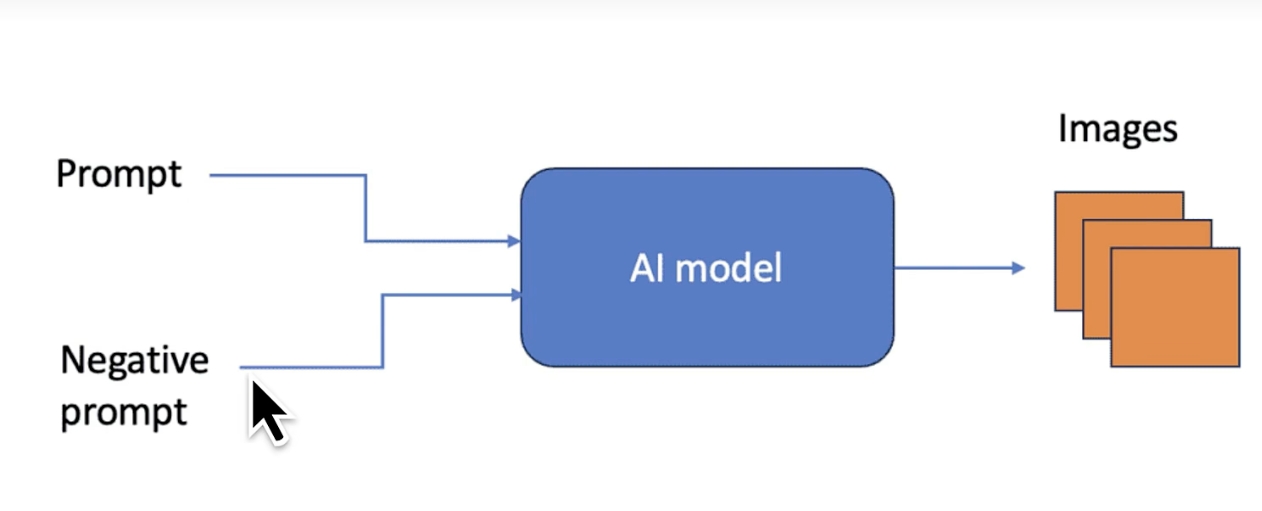
AI 文生图(Text-to-Image Generation)是指通过输入文本描述,生成对应图像的技术。文生图的整体流程:
- 文本编码:将输入的文本描述转换为向量表示,捕捉语义信息。
- 噪声生成与扩散过程:通过逐步向图像添加噪声,训练模型学习如何逆转噪声过程生成清晰图像。
- 采样(生成)过程:利用训练好的模型,从随机噪声开始,逐步去噪,生成符合文本描述的图像。
- 图像解码:将模型生成的潜在空间表示解码为真实图像。
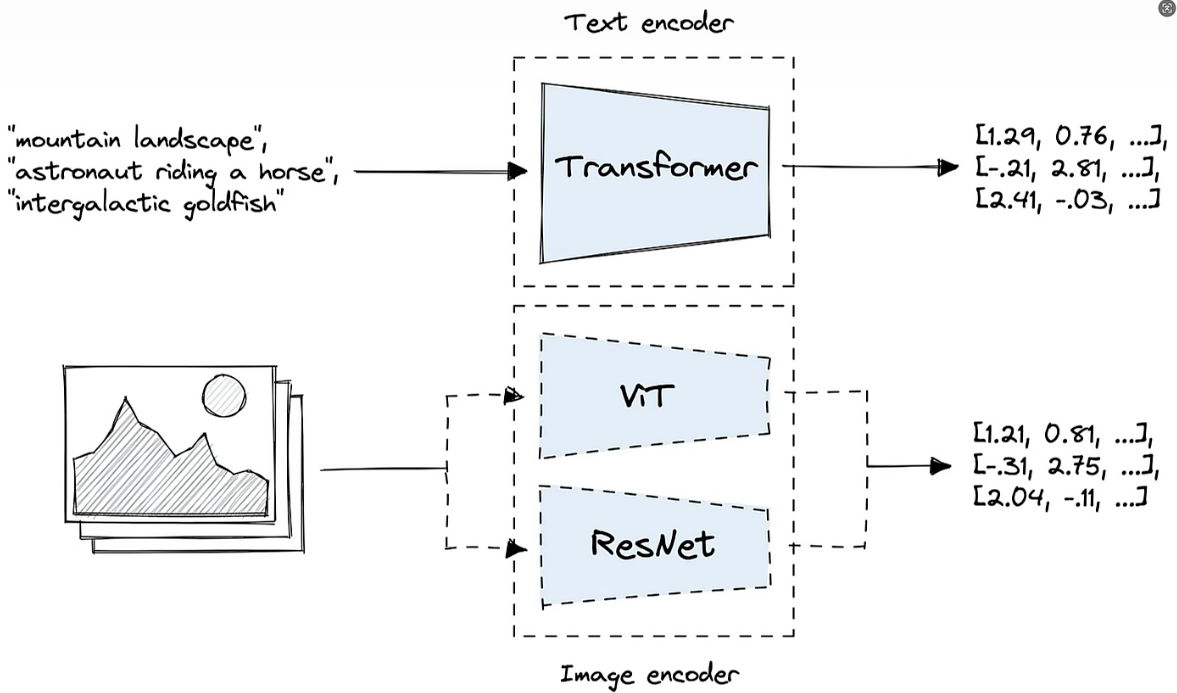
transformer模型将文本转换为特征向量,ViT或者ResNet将图像转换为特征向量;
扩散模型Diffusion Models
扩散模型是一类生成模型,通过模拟数据逐步添加噪声的过程,学习逆过程从噪声恢复数据。文生图中,扩散模型结合了 CLIP 文本编码作为条件输入,指导图像生成。
ComfyUI基础
提示词
正面提示词: 通常的结构是质量词汇 + 主体 + 氛围/环境词汇。这样输入的原因是因为:越靠前的词汇权重越高
- 质量词汇:高质量、杰作、非常清晰、极致细致等
- 主体:人物、动物、场景等主体
- 氛围/环境词汇:明亮、宁静、色彩丰富等
示例: Masterpiece, high quality, ultimate details, a girl with two ponytails, blue hair, school uniform, classroom background, anime style, 其中Masterpiece, high quality, ultimate details是质量词汇, classroom background, anime style是氛围/环境词汇
实践经验:一个个单词的描述比一句话的效果好,所以prompt通常用英文逗号隔开
负面提示词: 用于引导模型避免生成不相关或不符合要求的图像,通常包括质量词汇、不适当内容、低质量细节等。例如: missing limb来避免手指确实,distroted避免画面扭曲等。
一些常见的词,正向prompt通常会以下面几个词开头:
masterpiece, best quality, ultra-detailed, illustration, 负向提示词:deformed, distorted, disfigured:1.3), poorly drawn,bad anatomy,wrong anatomy,extra limb,missing limb,floating limbs
常用节点
K采样器(KSampler)
- 作用:在扩散模型的采样阶段,控制噪声去除的步骤和方式,影响生成图像的速度和质量。
- 原理:
- 扩散模型通过多个去噪步骤逐渐生成图像,K 采样器定义了具体的采样算法和参数(如采样步数、采样策略)。
- 常见采样器包括 DDIM、PLMS、Euler 等。
- 影响:
- 采样步数越多,生成图像质量越高,但速度越慢。
- 不同采样器在速度和质量上有权衡,需要根据具体需求选择合适的采样器。
参数:
- 采样步数(Steps):控制去噪过程的步数,越多越精细但越慢。通常在20-50之间。
- 采样器(Sampler):选择具体的采样算法,如 Euler、PLMS 等。
- CFG 重加权(CFG Scale):Classfier-Free Guidance Scale,用于平衡生成图像的质量和多样性,值越大越倾向于生成与提示词相关的图像。典型值 5~8,过大可能导致失真。
- 随机种子(Seed):确定随机过程的起点,相同种子生成的图像相同。
- 运行后操作(Control After Generate): 图像生成后的操作。
randomize表示每次生成都随机化参数,fixed表示不改变参数。 - 调度器(Scheduler): 定义了去噪过程的时间步长和噪声添加方式,影响图像生成的速度和质量。
- 降噪(Denoise): 表示是否在采样过程中添加噪声,一般开启。设置为1.0, 表示添加完全的高斯白噪声;设置为0,表示没有噪声,此时在图生图场景中就会按照原图输出;通常在图生图场景中,将值设置为0.35~0.6之间,会和原图比较相似。0.6 ~ 0.75之间就会给AI更多的创造空间。
常用的采样器:
- K-LMS:基于线性多步法(Linear Multistep),速度快,效果稳定。
- K-Euler:基于欧拉方法,生成图像细节丰富。
- K-Heun:改进的欧拉方法,平衡速度和质量。
- K-Euler a:带修正的欧拉方法,效果更细腻。
- K-DPM2:基于差分方程的方法,效果与 K-Euler 类似。
- K-DPM2 a:带修正的差分方程方法,效果更好
ComfyUI中通常可以设置为dpmpp_2m 或者 dpmpp_2m_sde, 除非模型特别指定
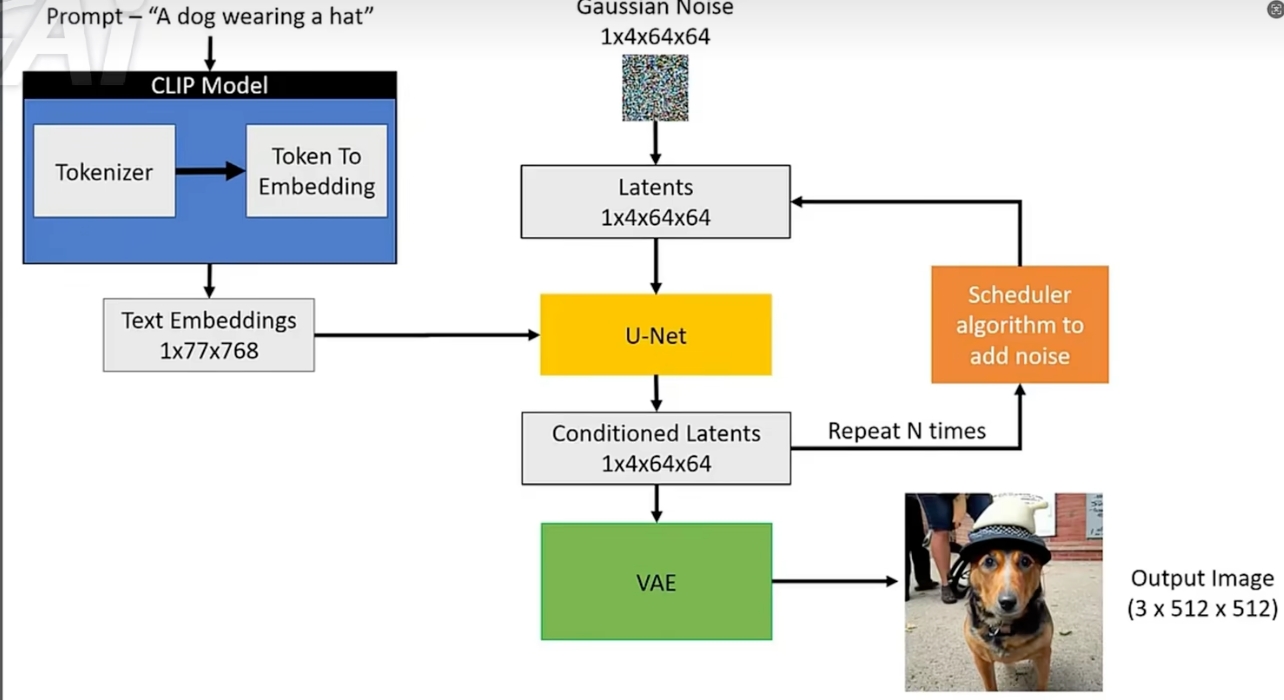
VAE解码 (VAE Decode)
VAE(Variational Auto Encoder、Decoder)
- 作用:将模型生成的潜在空间(latent space)表示解码为真实图像。
- 原理:
- VAE 是一种生成模型,包含编码器和解码器。
- 在文生图中,通常先将图像压缩到潜在空间,模型在潜在空间进行生成和去噪,最后通过 VAE 解码器还原成高分辨率图像。这样可以避免分辨率高的图片计算太耗资源。
不同的VAE压缩/解压效果不同,不当的VAE会导致图片失真/扭曲,或者有的VAE会导致发灰、发蓝、过饱和等(类似一个滤镜) 有的模型文件自带VAE
CLIP文本编码(CLIP Text Encoder)
- 作用:将文本描述转换为高维向量,作为生成模型的条件输入。
- 原理:
- CLIP(Contrastive Language-Image Pre-training)是 OpenAI 提出的一种多模态模型,联合训练文本和图像编码器,使得文本和对应图像的向量在同一空间中相近。
- 文本编码器将输入的自然语言文本转换为语义向量,指导图像生成模型生成符合描述的图像。
空Latent
在生成式模型(如基于潜在空间的模型)中,latent(潜在变量或潜在向量)表示模型内部用于描述数据本质特征的隐含表示。空 latent(empty latent)通常指的是一个“空白”或“零初始化”的潜在向量,是生成模型中生成过程的起点,模型从该潜在向量开始,通过逐步迭代(如扩散模型中的采样步骤)生成最终数据(如图像、文本等)。
Checkpoint加载 (Load Checkpoint)
Checkpoint表示模型权重文件(通常保存为ckpt或者safetensor等格式),存储训练好的模型参数是模型推理的基础。其中包含神经网络的权重和偏置,还可能包含编码器、解码器、文本编码器等多个模块的参数。
不同的模型是在不同的训练集上训练出来的,所以会学习到不同的风格、质量等。
操作
风格转绘
高清放大与细节添加
Lora
常用插件
1. EasyNegative
为了抑制
好用的模型
常用网站
国内网站