NLP基础
自然语言处理(Natural Language Processing,NLP)是一门借助计算机技术研究人类语言的科学。
NLP发展史
- 1970年代以前: 基于文法规则,问题:自然语言是上下文有关文法,规则无法穷举
- 1970年代 ~ 2006年: 基于数学模型和统计方法的自然语言处理方法开始兴起, 如“通信系统加隐马尔可夫模型”,有向图
- 2006年 ~ 2017年: 辛顿(Hinton)证明深度信念网络(Deep Belief Networks,DBN)可以通过逐层预训练策略有效地进行训练, 深度学习方法兴起(CNN, LSTM)
- 2017年 ~ 至今: Google 公司提出了 Attention 注意力模型,Transformer结构几乎一统江湖
统计语言模型发展史
Transformers模型
随着BERT和GPT的大火,Transformer 结构已经替代了循环神经网络 (RNN) 和卷积神经网络 (CNN),成为了当前 NLP 模型的标配。
注意力机制
Transformer模型的强大之处在于抛弃了之前广泛采用的循环网络和卷积网络,而采用了一种特殊的结构——注意力机制 (Attention) 来建模文本。
Attention
NLP 神经网络模型的本质就是对输入文本进行编码,常规的做法是首先对句子进行分词,然后将每个词语 (token) 都转化为对应的词向量 (token embeddings),这样文本就转换为一个由词语向量组成的矩阵
Transformers库使用
Transformers 库将目前的 NLP 任务归纳为几下几类:
- 文本分类:例如情感分析、句子对关系判断等;
- 对文本中的词语进行分类:例如词性标注 (POS)、命名实体识别 (NER) 等;
- 文本生成:例如填充预设的模板 (prompt)、预测文本中被遮掩掉 (masked) 的词语;
- 从文本中抽取答案:例如根据给定的问题从一段文本中抽取出对应的答案;
- 根据输入文本生成新的句子:例如文本翻译、自动摘要等
Transformers 库最基础的对象就是pipeline()函数,它封装了预训练模型和对应的前处理和后处理环节。我们只需输入文本,就能得到预期的答案。目前常用的pipelines 有:
- feature-extraction (获得文本的向量化表示)
- fill-mask (填充被遮盖的词、片段)
- ner(命名实体识别)
- question-answering (自动问答)
- sentiment-analysis (情感分析)
- summarization (自动摘要)
- text-generation (文本生成)
- translation (机器翻译)
- zero-shot-classification (零训练样本分类)
以情感分析和零训练样本分类为例:
| |
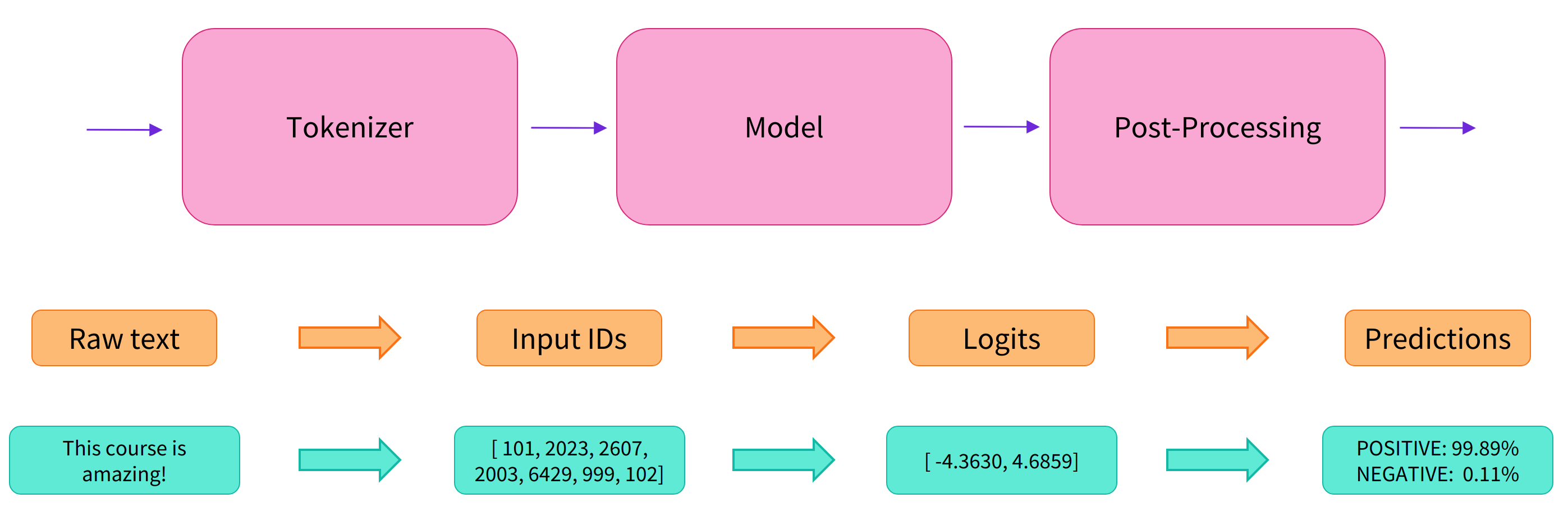
这些简单易用的 pipeline 模型实际上封装了许多操作, 主要是包含了以下步骤:
- 预处理 (preprocessing),将原始文本转换为模型可以接受的输入格式;
- 将处理好的输入送入模型;
- 对模型的输出进行后处理 (postprocessing),将其转换为人类方便阅读的格式。