基础
什么是BRAIN平台?
利用定量分析方法,BRAIN平台是一个全球金融市场回测模拟器,接受Alpha表达式作为输入,并绘制其盈亏(PnL)作为输出.每天根据历史日期对每个金融工具的输入表达进行评估,并据此构建投资组合。BRAIN平台根据表达式的值对每种金融工具进行投资。它进行交易(买入或卖空),并为每种工具分配权重。
什么是Alpha?
对于 WorldQuant 来说, Alpha 是一个数学模型,旨在预测各种金融工具的未来价格走势 。它将输入数据(价格-成交量、新闻、基本面等)转化为一个向量,其中的数值与我们每天要持有的每种金融工具的头寸和权重成正比。
BRAIN如何进行alpha回测
假设回测的表达是rank(-returns),并使用市场中性化、延迟1和衰减0设置, 则整个工具类似下图 (假设股票池中有8个股票):
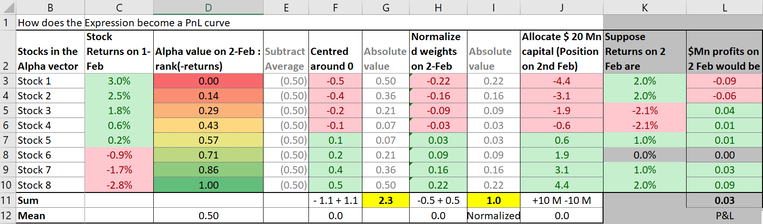
具体来讲:
- alpha求值: 根据表达式生成给定日期的alpha向量,对应上面的D列
- 中性化:从向量中的每个值中减去该组向量值的平均值。使得所有向量值的总和=0,对应上面的F列。
- 权重标准化:将生成的值缩放或"标准化",使得alpha向量值的绝对值总和为1。通常做法:原始值除以绝对值加和, 对应上面的H列。
- 分配资金:将资金根据3中得到的归一化权重分配资金,正值做多负值做空,NAN表示不分配资金。这被称为多空市场中性化,这是创建这些预测模型或alpha的支柱。使用这种技术,策略可以在市场走势方向不确定的情况下实现盈利.
- 收益计算: 根据当天观察到的股票回报率计算alpha生成的下一天的收益,例如K列表示实际回报率,则最终收益结果为L列。
- 回测周期: 对历史时间跨度IS中每个日期重复计算,得到累积PnL图表
- 在BRAIN平台上,我们对回测的每一天都使用恒定的账面大小,无论你的投资组合是赚钱还是亏钱。
- 如果使用行业中心化,则回测器会根据行业分组的情况对每个组执行相同的操作,最后将每个组的PnL相加以获得alpha的每日PnL,并创建累积PnL图表。
什么是好的Alpha?
一个好的阿尔法最好是有持续增长的净值,高的年回报率,更重要的是,在累积利润图中的波动很小。如果标准差较低,图表中的波动就会较小。如果图表中显示出高波动/波幅,尽管回报率很高,那么阿尔法就不会被认为是足够好。
WorldQuant旨在开发具有低波动性和低风险的股票多空市场中性阿尔法指数。其目标是最大限度地减少市场风险,并从两只股票的价差变化中获利。
Alpha状态
在成功模拟Alpha之后,Alpha会被标记为“UNSUBMITTED ”。成功提交之后,Alpha会显示“ACTIVE”状态。研究顾问的状态为“ACTIVE”的Alpha可以积累weight并对季度薪酬产生贡献,如同在顾问条款中描述的那样。“ACTIVE"状态会一直保持直到该Alpha所用到的数据集退役或者WorldQuant根据自己的裁量退役这个Alpha。 如果该Alpha所用的数据集不再可用或者该Alpha在OS阶段一直表现不佳,这个Alpha的状态会变为"DECOMMISSIONED”。退役后的Alpha不再积累weight, 也不在对顾问季度薪酬产生贡献

模拟设置参数说明
- Delay: 延迟指数据可用性相对于决策时间的时间差。换句话说,延迟(Delay)是指一旦我们决定持仓,我们可以交易股票的时间假设。假设您在今天的交易结束前看到数据,决定要买入股票。我们可以选择积极的交易策略,在剩余时间内交易股票。在这种情况下,持仓基于当天可用的数据(今天)。这称为“延迟 0 回测”。或者,我们可以选择一种保守的交易策略,并在第二天(明天)交易股票。然后,持仓是在明天实现的,基于今天的数据。在这种情况下,有一个 1 天的滞后。这称为“延迟 1 回测”
- Decay: 衰减。通过将今天的值与前n天的值执行线性衰减函数,函数如下:
$$ Decay_linear(x,n)=\frac{x[date]n+x[date-1](n-1)+\cdots+x[date-n-1]}{n+(n-1)+\cdots+1} $$
衰减是减少交易成本或换手率的非常重要的因素,因为它包括前几天的信息,防止alpha过于反应灵敏, 但是也可能削弱信号。
- Neutralize: 中心化。中性化是用于使我们的策略市场/行业/子行业中性的操作。当中性化 =“市场”时,它执行以下操作: $Alpha = Alpha – mean(Alpha)$, 其中alpha是权重向量. 操作后,它使 Alpha 向量的平均值为零。因此,与市场相比没有净头寸。换句话说,多头暴露完全抵消了空头暴露,使我们的策略市场中性。当中性化 = industry或subindustry时,Alpha 向量中的所有股票都分组到对应的行业或子行业中,并分别应用中性化。
- 在设置中配置Neutralize和在脚本中使用group_neutralize效果类似,脚本中使用group_neutralize时建议设置Neutralize为None, decay和truncation设置为0,例如:
- Truncation: 截断,表示整体组合中每只股票的最大权重。当它设置为 0 时,表示没有限制。允许输入的截断值:0 <= x <= 1 的浮点数。截断旨在防止过度暴露于个别股票的波动。推荐的设置值为 0.05 到 0.1(涵盖 5%-10%)。
- Pasteurize: 巴氏化,是指过滤掉不属于当前股票池的工具数据,让数据更聚焦。On表示仅考虑当前股票池内的数据,将为未在回测设置中选择的股票池中的工具将输入转换为 NaN。可以使用
pasteurize进行手动巴氏化,例如使用以下设置:Universe TOP500,Pasteurize:“Off”, 则group_rank(pasteurize(sales_growth),sector) - group_rank(sales_growth,sector)表示第一组排名中的消毒运算符将输入消毒为 Alpha 股票池(TOP500)中的股票,而第二组等级排名将 sales_growth 在所有股票中进行排名,两者做差。 - Universe: 股票池是一个预选的股票集合。越小的股票池,表示包含流动性和市值较高的股票越多。流动性越高,交易越频繁,意味着股票市场对信息的反映越快。因此,较小的市场空间通常表现出相对较弱的 Alpha 信号。
- NaN Handling: 当该值为On时,对于时间序列运算符,如果所有输入都为 NaN,则返回 0。对于每组返回一个值的群组运算符(例如 group_median、group_count),如果一只股票的输入值为 NaN,则返回该组的值. 而为Off时,则保留 NaN。对于时间序列运算符,如果所有输入都为 NaN,则返回 NaN。对于群组运算符,如果一只股票的输入值为 NaN,则返回 NaN。在这种情况下,研究人员应手动处理 NaN。
一些概念
- PnL: Profit and Loss, 损益,在brain平台一般表示累计盈亏
- IS, Semi-OS, OS: 分别表示Inside Sample, Semi-Outside Sample, Outside Sample.
- IR: 信息比率Information Ratio, 在BRAIN平台中,定义为组合每日平均收益与这些收益的波动率之比,即$IR=\frac{mean(PnL)}{stdev(PnL)}$。与固定的开始和结束日期相比 ,In Sample(IS) 是一个5年的滚动窗口,每天都会改变。In Sample (IS)回测从当前日期的7年前开始,到2年前结束。最近一年的数据被隐藏并用于评分和测试。在“我的Alpha页面”的“OS”选项卡中显示的统计数据将随着数据变得可用而逐渐补全。完全隐藏最后两年的数据会提高Alpha在OS表现和评分方面的置信程度。

- Sharpe Ratio: 可以看做是IR统计量的年化版本,该比率衡量Alpha策略的超额回报(或风险溢价)与其波动性之间的比率。它将PnL的平均值除以PnL的标准差, 公式为:$Sharpe Ratio=\sqrt{252}\frac{Mean(PnL)}{Stdev(PnL)}$,其中252是一年中美国交易日(市场开放日)的平均数量。Sharpe Ratio或信息比率(IR)越高,Alpha策略潜在的回报越稳定,而稳定性是一个理想的特征。BRAIN平台的Sharpe Ratio通过要求为大于1.25来判断是否通过.
- IC: Information Coefficient是衡量量化因子预测能力的一种指标。通常使用 Spearman 秩相关系数或 Pearson 相关系数来计算。一个较高的 IC 表示因子对未来收益有较好的预测能力。
- Spearman 秩相关系数:用于衡量因子值与实际收益之间的秩相关性,适用于非线性关系。
- Pearson 相关系数:用于衡量因子值与实际收益之间的线性相关性,适用于线性关系。
| |
回测结果Simulation Results说明
在回测结果页面中,您会发现一个评级面板,位于结果的统计选项卡中,标明了卓越、优秀、良好、一般或需要改进等评级,取决于您的Alpha的Fitness分数,具体如下所示:
| Label | Fitness for Delay 1 | Fitness for Delay 0 |
|---|---|---|
| Spectacular | > 2.5 | > 3.25 |
| Needs Improvement | <= 1 | <= 1.3 |
| Good | > 1.5 | > 1.95 |
| Excellent | > 2 | > 2.6 |
| Average | > 1 | > 1.3 |
常见的一些指标的说明:
- 年化收益:特定期间内一种证券或组合的收益或损失。在BRAIN平台中,收益率=年化PnL/账户本金大小的一半.
- 信息比率IR, 夏普比率:参考上方
- 适应性Fitness: 是收益、换手率和Sharpe的函数: $Fitness=Sharpe\cdot \sqrt\frac{abs(Returns)}{max(Turnover, 0.125)}$ 。良好的Alpha具有高适应度。您可以通过增加Sharpe(或收益)并降低换手率来优化Alpha的表现。
- 自相关性Self Correlation:
Fast Expression语法
基础
运算符Operators
基础运算符
| 运算符名称 | 语法 | 描述 | 参数说明 |
|---|---|---|---|
| 绝对值 | abs(x) | 返回 x 的绝对值 | - |
| 加法 | add(x, y, filter=false) 或 x + y | 对输入值求和(至少需 2 个输入) | filter=true 将 NaN 替换为 0 |
| 除法 | divide(x, y) 或 x / y | 返回 x 除以 y 的结果 | - |
| 倒数 | inverse(x) | 返回 1 / x | - |
| 自然对数 | log(x) | 返回 x 的自然对数(例如 Log(high/low) 计算价格比值的对数) | - |
| 最大值 | max(x, y, ...) | 返回所有输入中的最大值(至少需 2 个输入) | - |
| 最小值 | min(x, y, ...) | 返回所有输入中的最小值(至少需 2 个输入) | - |
| 乘法 | multiply(x, y, ..., filter=false) 或 x * y | 对输入值求积(至少需 2 个输入) | filter=true 将 NaN 替换为 1 |
| 幂运算 | power(x, y) | 返回 x 的 y 次幂 | - |
| 反向值 | reverse(x) | 返回 -x | - |
| 符号函数 | sign(x) | 若输入为 NaN 返回 NaN;否则返回 x 的符号(-1, 0, 1) | - |
| 带符号的幂 | signed_power(x, y) | 返回 x 的 y 次幂,并保留 x 的符号 | - |
| 平方根 | sqrt(x) | 返回 x 的平方根 | - |
| 减法 | subtract(x, y, filter=false) 或 x - y | 返回 x 减 y | filter=true 将 NaN 替换为 0 |
| 稀疏化 | densify(x) | 将分组字段的多个桶合并为更少的可用桶以提高计算效率 | - |
逻辑运算符
| 运算符名称 | 语法 | 描述 | 参数说明 |
|---|---|---|---|
| 逻辑与 | and(input1, input2) | 仅当两个输入均为真时返回 true | - |
| 逻辑或 | or(input1, input2) | 任一输入为真时返回 true | - |
| 逻辑非 | not(x) | 输入为真返回 false,输入为假返回 true | - |
| 小于 | input1 < input2 | 若 input1 < input2 返回 true | - |
| 小于等于 | input1 <= input2 | 若 input1 <= input2 返回 true | - |
| 等于 | input1 == input2 | 若两个输入相等返回 true | - |
| 大于 | input1 > input2 | 若 input1 > input2 返回 true | - |
| 大于等于 | input1 >= input2 | 若 input1 >= input2 返回 true | - |
| 不等于 | input1 != input2 | 若两个输入不相等返回 true | - |
| 是否为 NaN | is_nan(input) | 若输入为 NaN 返回 1,否则返回 0 | - |
| 条件选择 | if_else(input1, input2, input3) | 若 input1 为真返回 input2,否则返回 input3 | - |
时间序列运算符
| 运算符名称 | 语法 | 描述 | 参数说明 |
|---|---|---|---|
| 移动平均值 | ts_mean(x, d) | 返回过去 d 天内 x 的平均值 | - |
| 滚动求和 | ts_sum(x, d) | 返回过去 d 天内 x 的累加值 | - |
| 延迟值 | ts_delay(x, d) | 返回 d 天前的 x 值 | - |
| 差值计算 | ts_delta(x, d) | 返回当前 x 值减去 d 天前的 x 值(即 x - ts_delay(x, d)) | - |
| 标准差 | ts_std_dev(x, d) | 计算过去d 天内x的标准差 | - |
| Z 分数 | ts_zscore(x, d) | 计算标准化分数:(x - ts_mean(x,d)) / ts_std_dev(x,d),用于减少异常值 | - |
| 最大值索引 | ts_arg_max(x, d) | 返回过去 d 天内最大值对应的相对天数索引(当前天为 0) | - |
| 最小值索引 | ts_arg_min(x, d) | 返回过去 d 天内最小值对应的相对天数索引(当前天为 0) | - |
| 数据回填 | ts_backfill(x, lookback=d, k=1) | 用过去 d 天内第 k 个非 NaN 值填充当前 NaN | ignore="NAN" 控制填充规则 |
| 相关系数 | ts_corr(x, y, d) | 返回 x 和 y 在过去 d 天内的相关系数 | - |
| 滚动排名 | ts_rank(x, d, constant=0) | 对过去 d 天内的 x 值排序,返回当前值的排名 + constant | constant 为排名偏移量 |
| 移动中位数 | ts_median(x, d) | 返回过去 d 天内 x 的中位值 | - |
横截面运算符
| 运算符名称 | 语法 | 描述 | 参数说明 |
|---|---|---|---|
| 标准化 | normalize(x, useStd=false) | 减去均值(若 useStd=true 则除以标准差) | limit 限制标准化范围 |
| 排名 | rank(x, rate=2) | 返回 0.0~1.0 的均匀分布排名(rate=0 表示精确排序) | rate 控制排名精度 |
| 缩放 | scale(x, scale=1) | 将输入缩放到指定规模,可分别设置多头和空头比例(longscale, shortscale) | - |
| 截尾处理 | winsorize(x, std=4) | 将 x 限制在均值的 ±std 倍标准差范围内 | - |
| 横截面 Z 分数 | zscore(x) | 计算横截面 Z 分数:(x - 均值) / 标准差 | - |
分组运算符
| 运算符名称 | 语法 | 描述 | 参数说明 |
|---|---|---|---|
| 组中性化 | group_neutralize(x, group) | 消除组内(如行业、国家)的影响,使 Alpha 在组内中性化 | group 指定分组字段 |
| 组 Z 分数 | group_zscore(x, group) | 计算组内 Z 分数:(x - 组均值) / 组标准差 | - |
| 组内排名 | group_rank(x, group) | 在组内对每个元素分配排名 | - |
| 组内归一化 | group_scale(x, group) | 将组内值缩放到 0~1 范围:(x - 组最小值) / (组最大值 - 组最小值) | - |
向量运算符
| 操作符 | 描述 |
|---|---|
vec_avg(x) | 计算向量x的平均值 |
vec_choose(x,nth=k) | 从向量x中选取第k个元素(从0开始索引) |
vec_count(x) | 向量x中的元素数量 |
vec_ir(x) | 向量x的信息比率(均值/标准差) |
vec_kurtosis(x) | 向量x的峰度 |
vec_max(x) | 向量x中的最大值 |
vec_min(x) | 向量x中的最小值 |
vec_norm(x) | 向量x所有绝对值的总和 |
vec_percentage(x,percentage=0.5) | 向量场x的百分位数 |
vec_powersum(x,constant=2) | 向量x的幂次和 |
vec_range(x) | 向量x中最大元素与最小元素的差值 |
vec_skewness(x) | 向量x的偏度 |
vec_stddev(x) | 向量x的标准差 |
vec_sum(x) | 向量x的总和 |
其他运算符
| 类别 | 运算符名称 | 语法 | 描述 |
|---|---|---|---|
| 转换运算 | 分桶 | bucket(rank(x), range="0,1,0.1") | 将浮点值转换为自定义区间的索引(用于分组) |
| 条件交易 | trade_when(x, y, z) | 仅在满足条件时更新 Alpha 值(如 y 触发时使用 z 逻辑) |
一些重要运算符详解
rank(x)
说明:排序运算符将给定股票的输入数据x的值在所有股票中进行排名,并返回均匀分布在0.0和1.0之间的浮点数。 例如:五个资产的原始alpha值分别是[1,2,3,20,100],如果直接按照这个值执行仓位分配,会导致最后一个资产分配比重过大,风险较大,rank后的值为[0,0.25.0.5,0.75,1]
数据
数据基础
数据集是数据字段的集合。数据集可以通过其名称(文本格式,较长且具有解释性)或其数据集 ID(简短的字母数字格式,仅适用于高级脚本)来识别。
- matrix类型字段:基本类型的字段,每个日期和工具只有一个值,在模拟中使用这种字段没有特殊语法。矩阵字段的一些示例包括:收盘价、收益、市值。
- vector类型字段:表示某个时间一个资产有多个值的字段类型,例如每天一个股票可能有多个新闻/事件,矢量数据字段必须先使用矢量运算符转换为矩阵数据字段,然后才能与其他运算符和矩阵数据字段一起使用。否则,将返回错误消息。
如何理解数据集
参考:6-ways-to-quickly-evaluate-a-new-dataset
在模拟中设置Neutralize为None, Decay为0,然后进行如下表达式的模拟,并使用结果摘要中的long-count和short-count来获取参数的洞察。
| Sr. No | Expression | Insight |
|---|---|---|
| 1 | datafield | 得到覆盖率% coverage数据,计算方法(long-count + short-count)/ universe size, 而且根据long-count和short-count得到正负值的概况 |
| 2 | datafield != 0 ? 1 : 0 | 覆盖率 。长计数表示每日平均非零值 |
| 3 | ts_std_dev(datafield,N) != 0 ? 1 : 0 | 唯一数据的频率 (每日、每周、每月等)。 有些数据集会填充缺失值,而有些则不会。给定的表达式可用于通过改变 N(天数)来查找唯一数据字段的更新频率。 对于具有季度唯一数据频率的数据字段,当 N = 66(季度)时,其长计数 + 短计数值会接近其实际覆盖率。当 N = 22(月)时,长计数 + 短计数值会更低(约为覆盖率的 1/3 ),而当 N = 5(周)时,长计数 + 短计数值会更低。 |
| 4 | abs(datafield) > X | 数据字段的边界 。改变 X 的值并查看长计数。例如,X=1 表示该字段是否被标准化为 -1 到 +1 之间的值 |
| 5 | ts_median(datafield, 1000) > X | 数据字段 5 年内的中位数 。改变 X 的值并查看长计数。类似的过程可用于检查数据字段的平均值。 |
| 6 | X < scale_down(datafield) && scale_down(datafield) < Y | 数据字段的分布 。scale_down 充当 MinMaxScaler 函数,可以保留数据的原始分布。X 和 Y 的值在 0 到 1 之间变化,可以用来检查数据字段在其范围内的分布情况。 |
数据处理技巧
- 覆盖率是指给定数据字段具有定义值的所有品种占现有品种总数的比例。低覆盖率字段可以通过使用回填运算符((例如 ts_backfill、kth element、group_backfill 等)来处理。
sentiment1数据集
sentiment1 数据集将情绪指标与美国上市公司的盈利预测和意外情况(Earning Estimation and surprises)相结合, 提供了对市场情绪、分析师共识和基于收益的信号的洞察,核心字段关键领域包括情绪得分、分析师买入/卖出建议的比率、盈利意外以及分析师估计之间的离散度。
情绪分数是动态高频的,而分析师和收益指标则是低频较慢变化的;所以建议使用decay操作来管理高频的情绪数据,并在使用长loopback时要谨慎(因为较旧的事件会失去相关性)。
这个数据集在TOP3000上覆盖了大约2000条,更建议使用流动性更强的TOP1000和TOPSP500.
结果评估
结果报告
在BRAIN平台中,执行完模拟后会输出累计PnL图表,IS(样本内测试)概要。
IS(样本内测试)回测使用5年时间范围内的数据,测试您的Alpha策略在历史时期的表现如何。模拟后,您将看到IS概要行,其中包括6个指标:Sharpe、Turnover、Fitness、Returns、Drawdown和Margin。
技巧
如何提高alpha的效果
sharpe提升:(1)使用较低的decay (2)交易流动性更好的股票池,例如使用TOP200, 而不是TOP3000 (3) 适当增加alpha的波动性 (4)利用新闻和分析师数据集来获取创新的 Alpha 理念
turnover降低:
如何降低alpha的相关性?
首先alpha的相关性高不一定是坏事,这意味着已经实现了类似的想法,所以方向大概率不是错的(假设最初的alpha表现良好)。此时,不应该丢弃这个alpha, 而是考虑使用变形等技巧,例如:
- 使用不同的数据字段:例如使用
open,vmap来代替close - 使用不同的运算符: 例如将运算符从减法改为除法,例如:
close - open变为close/open - 使用不同的分组:例如计算每个部门/行业而不是整个市场的动量,按照规模(大盘股与小盘股)或波动性(高与低)分组
- 引入不同窗口大小的滚动平均值
- 测试alpha与基本信号(市盈率)的组合
如何平滑PnL曲线减少突然波动?
常见的原因是:(1)Alpha值从 NaN 变为 non-NaN,反之亦然。可以使用backfill函数来解决这个问题 (2) Alpha值快速变化,可以采用衰减或取平均值可以帮助你使曲线更平滑 (3)可能在某个股票上投入了太多资金,可以考虑使用截断。
如何过度拟合?
可以考虑使用以下的方式来降低过度拟合风险并提升alpha稳健性:
- rank test: 将alpha转换为rank排序值
- binary test: 将alpha转换为-1,+1
- sub/super universe test: 使用更大或者更小的股票池进行测试,验证鲁棒性
如何选择合适的中性化?
建议使用进行中性化操作,无论是通过设置还是手动使用group_neutralize;
以下是基于数据集类别的neutralize建议:
| 数据集 | 市场 | 行业板块 | 行业 | 子行业 | 备注 |
|---|---|---|---|---|---|
| Fundamental Datasets | ✔️ | 公司基本面数据对股价的影响因行业而异,因此建议进行行业中性化处理。 | |||
| Analysts Datasets | ✔️ | 分析师数据集提供了未来基本面数据的预测,因此同样建议进行行业中性化处理。 | |||
| Model Datasets | ✔️ | ✔️ | ✔️ | ✔️ | 模型数据集可能因可用子类别而有很大差异。建议根据子类别尝试不同的中性化类别以获得最佳结果。 |
| News Datasets | ✔️ | 新闻对不同公司的影响可能因其子行业而有很大不同。建议尝试对子行业进行中性化处理。 | |||
| Option Datasets | ✔️ | ✔️ | 对于期权数据集,建议对市场或行业板块进行中性化处理,因为期权对股价的影响在广泛行业中几乎相似。 | ||
| Price Volume Datasets | ✔️ | ✔️ | 通用策略在所有工具中都表现良好,使用行业或子行业中性化可能会降低性能。 | ||
| Social Media Datasets | ✔️ | ✔️ | 社交媒体影响可能因公司所属子行业而不同,建议尝试在子行业层面进行中性化处理。也可根据新闻的广泛适用性考虑行业层面中性化。 | ||
| Institutions Datasets | ✔️ | ✔️ | 取决于可用机构数据集的类型、提供者及其影响。建议测试行业板块或行业中性化效果。 | ||
| Short Interest Datasets | ✔️ | 建议对空头利息数据集进行行业中性化处理。也可尝试其他中性化方式。 | |||
| Insider Datasets | ✔️ | ✔️ | 内幕消息不一定会以相同方式影响每家公司,因其取决于行业或子行业。建议对这些类别进行中性化处理。 | ||
| Sentiment Datasets | ✔️ | ✔️ | 与内幕/社交媒体类似,情绪可能因行业或子行业而对不同公司产生不同影响,建议对这些类别进行中性化处理。 | ||
| Earnings Datasets | ✔️ | 对于盈利数据集,建议进行行业中性化处理,类似于基本面数据集。 | |||
| Macro Datasets | ✔️ | ✔️ | ✔️ | 行业板块/市场/行业是宏观经济活动,对这些类别进行中性化处理效果最佳。子行业间差异不大。 |
权重测试Weight Test失败
权重测试只是衡量 Alpha 基金单只股票的资本集中度。在 BRAIN 中,该限制为总账簿规模的 10%。权重测试对于限制股价波动造成的回撤风险至关重要,尤其是在样本外。所以一个简单的方式就是设置一个较低的Truncation截断值.
导致权重测试失败的主要因素之一是覆盖率。例如,如果在模拟过程中的任何时候,多头或空头仓位的股票数量少于 10 只,或者股票总数少于 20 只。通常,覆盖率低和/或多空仓位不平衡的 Alpha 会失败。处理的方式:(1)使用类似ts_backfill等函数进行缺失数据的补齐,具体的参数值需要根据参数的情况来设定,例如季度更新的数据可以使用30,60的参数 (2)使用is_nan(),last_diff_value*(),day_from_last_change()来进行回填
还有一类是权重过于集中的情况,此时可以考虑使用rank、ts_rank、 zscore 和 ts_zscore 来移除此类异常值,或者考虑使用截断。
Subuniverse Test 子股票池测试
它用于检验 Alpha 信号在较小股票池中是否持续存在。通过验证 Alpha 在流动性较高、信号更难生成的宇宙中是否有效,它评估了 Alpha 的稳健性。如果 Alpha 指标未能通过这项测试,它很可能在交易量较低的股票上有效,这使得实际操作起来非常困难。
常用缩写
- eps: Earnings per share 每股收益
- IV: Implied volatility 隐含波动率